Don’t freak out, but we’re surrounded by normal distributions.
They’re in our heights; our weights; our sampling means; our fever-dreams; our Galton Boards…
Every normal is a variation on the same bell-curved theme. Just specify two parameters—the mean, i.e., the center of the distribution, and the variance, which measures its breadth—and you’ve got a normal distribution. They’re one big clan, with a strong family resemblance.
But—for me, at least—this raises a question: Who is the matriarch of the family? Which normal distribution is the founding member, the Mitochondrial Eve, the universal common ancestor?
There’s an “official” answer, one that I’ve taught to students: The standard normal distribution has mean 0 and variance 1.
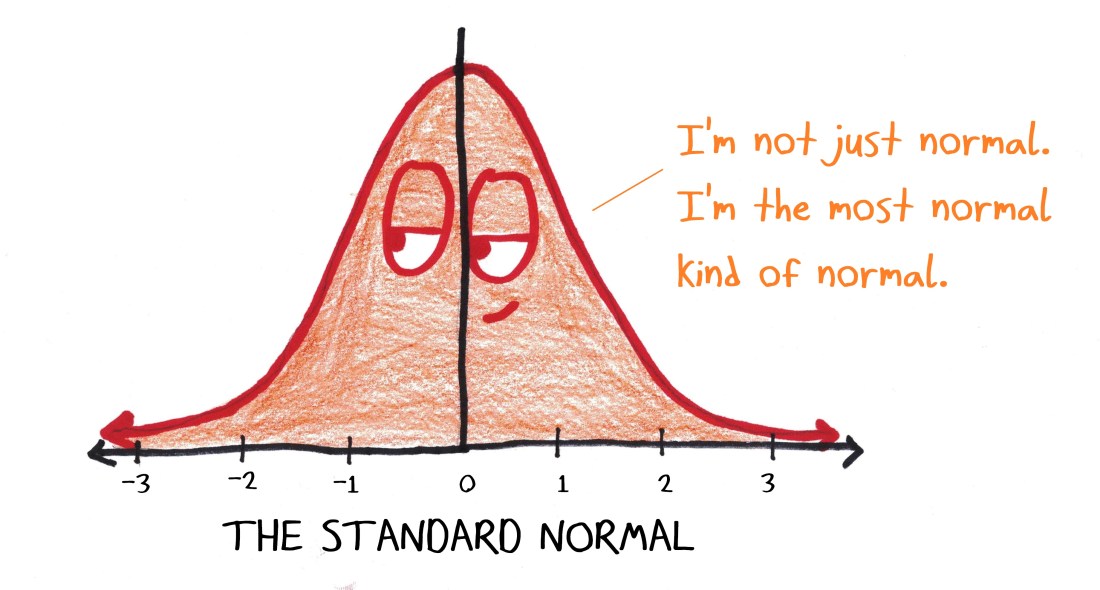
Why? Because zero and one are very simple numbers. (No offense meant, Zero and One! It’s a compliment.) Here, the “zero” ensures the distribution is symmetric around the y-axis (a very nice property), while the “one” ensures that the standard deviation (i.e., the square root of the variance) is also one. That’s cool, because a lot of our work with normals consists in counting standard deviations. It’s easy to count by ones.
But there’s a downside. This lovely, balanced graph can be described only by a lopsided, fraction-infested equation.
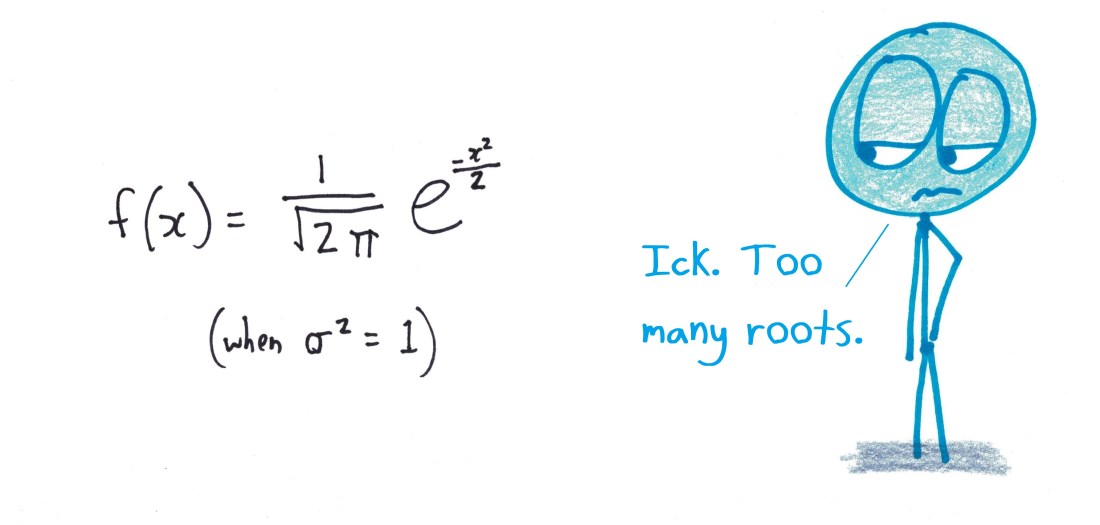
It’s an all-too-common experience in math. Simplifying over here winds up complicating things over there. It’s like there’s a bubble under the rug of math: you can push it elsewhere, but you can’t make it go away.
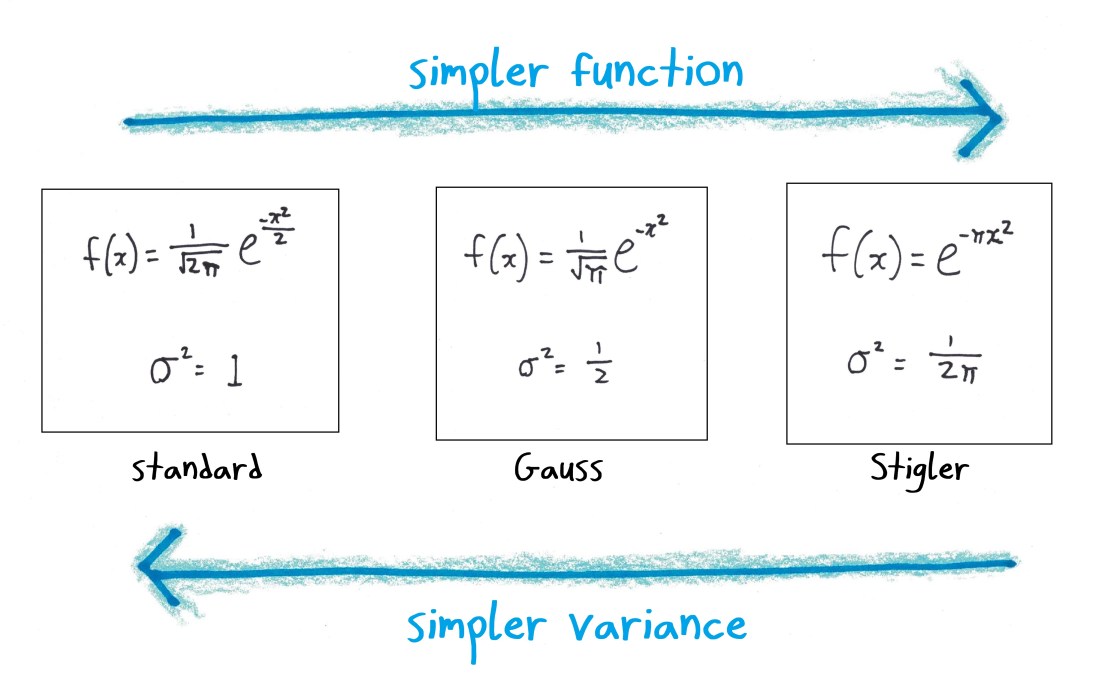
Of course, “standards” are arbitrary. Some countries drive on the left; some, on the right; and in some, drivers weave like Quidditch players in pursuit of invisible, multitudinous snitches. Now, in the case of the normal distribution, some mathematicians have pushed for other standards. For example, Carl Gauss preferred the distribution with variance ½.
Why? Well, presumably because the equation for the graph is a good bit simpler:

Stephen Stigler, who has written books on the history of statistics, proposes yet another definition. He wants to dub as “standard” the distribution with variance 1/2π, which has the advantage of an even simpler equation:
In all this, we’re playing with notation. Do you want your obnoxious bubble of extra symbols to pop up over here, in the variance, or over there, in the density function? It’s a frothy, fun, splashy game—but perhaps a bit kiddie. Symbols only symbolize. They aren’t the math itself.
Is there any true substance to the bubble-pushing game?
I am happy to report: Yes! It leads right to the heart of mathematics: the act of building from simple assumptions to impressive conclusions.
From Euclid’s day, mathematicians saw this as a start-to-finish process: assume first, conclude later. The choice of axioms was thus all-important. Am I making the right assumptions? What can I truly take for granted? Is Euclid’s fifth postulate really necessary, or can we prove it from the other four? If cogito, does it follow, ergo, that sum? You had to start with solid truth—or everything would crumble.
Our modern perspective, as Barry Mazur explains, is different:
Nowadays, with Hilbert’s formulation of formal systems, we understand that we can start anywhere, provided – of course – that we don’t end up with a contradiction. This shift of emphasis is curious: the ancients worried so much about beginnings, the moderns about endings.
These days, we care less where we start. I can assume A to prove B, or assume B to prove A. I can choose rich, information-dense definitions, and then work hard to verify their consistency; or I can choose lean, minimalist definitions, and work hard to deduce the desired properties. The ancients built their logical towers upward from the foundation, but the moderns feel free to extrapolate downwards from the top floor—even to flip the structure upside down.

An example (again from Mazur—I’ve been feasting on his essays): There are two ways to define the bisector of an angle.
- The line that divides an angle into two equal angles.
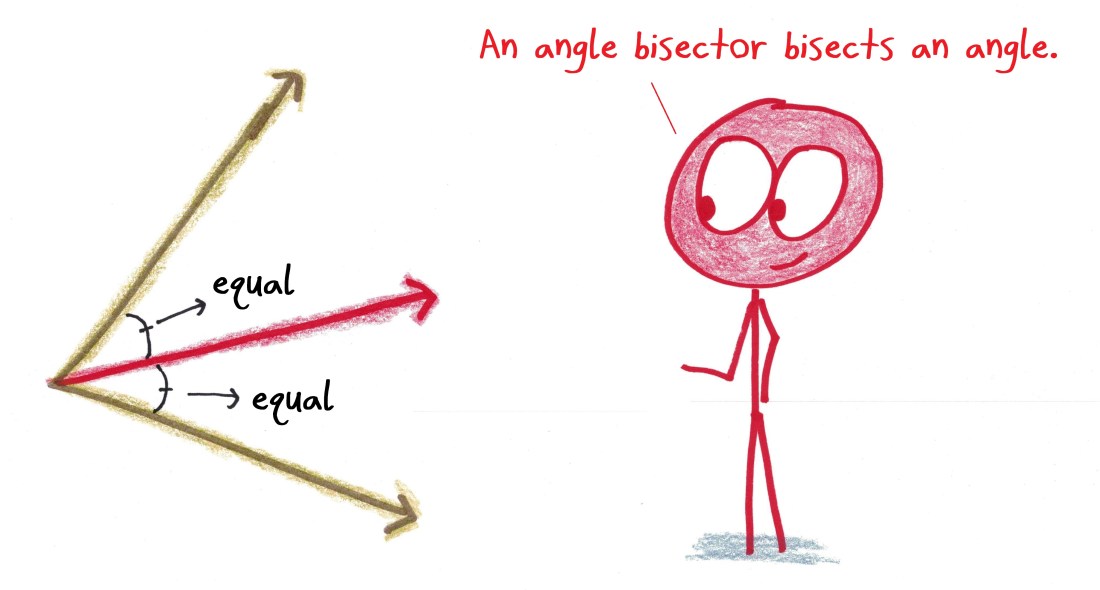
- The set of points equidistant from the angle’s two rays.
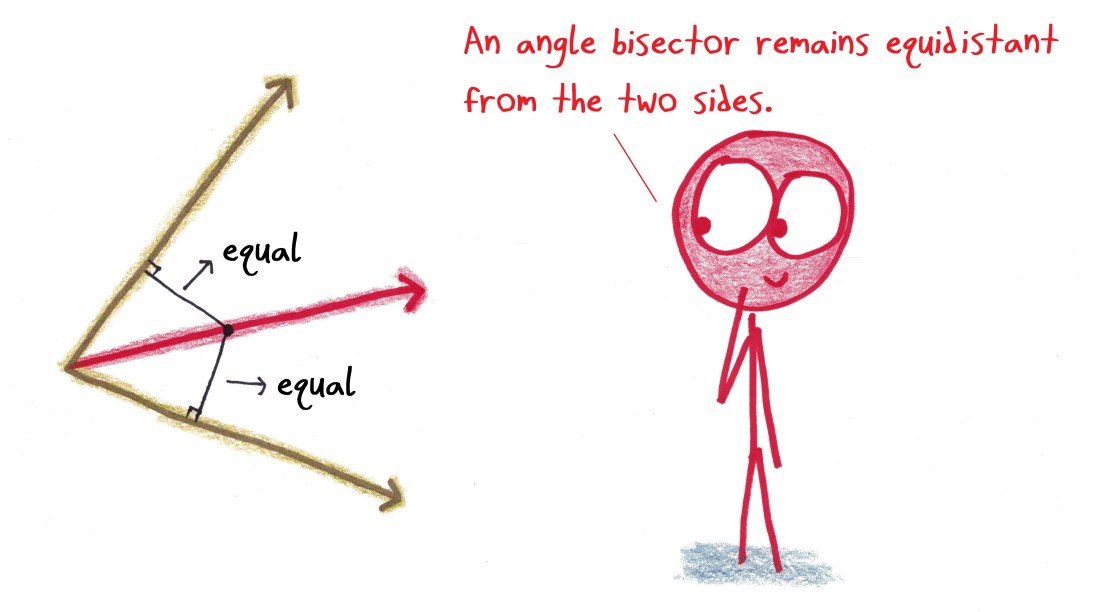
I find the first definition more natural: to “bisect” something is to split it in half. I like it when the definition matches the name (a “walkie talkie” is for walking while talking; a “pooper scooper” is for scooping of pooping; a “candelabra” is a magic spell for lighting candles…).
But the second definition has its merits, too. It names a property just as essential as the “split an angle in half” property. The equidistance idea underlies the ruler-and-compass construction of the angle bisector, and lets you explain in a jiffy why a triangle’s three angle bisectors always meet at a single point:
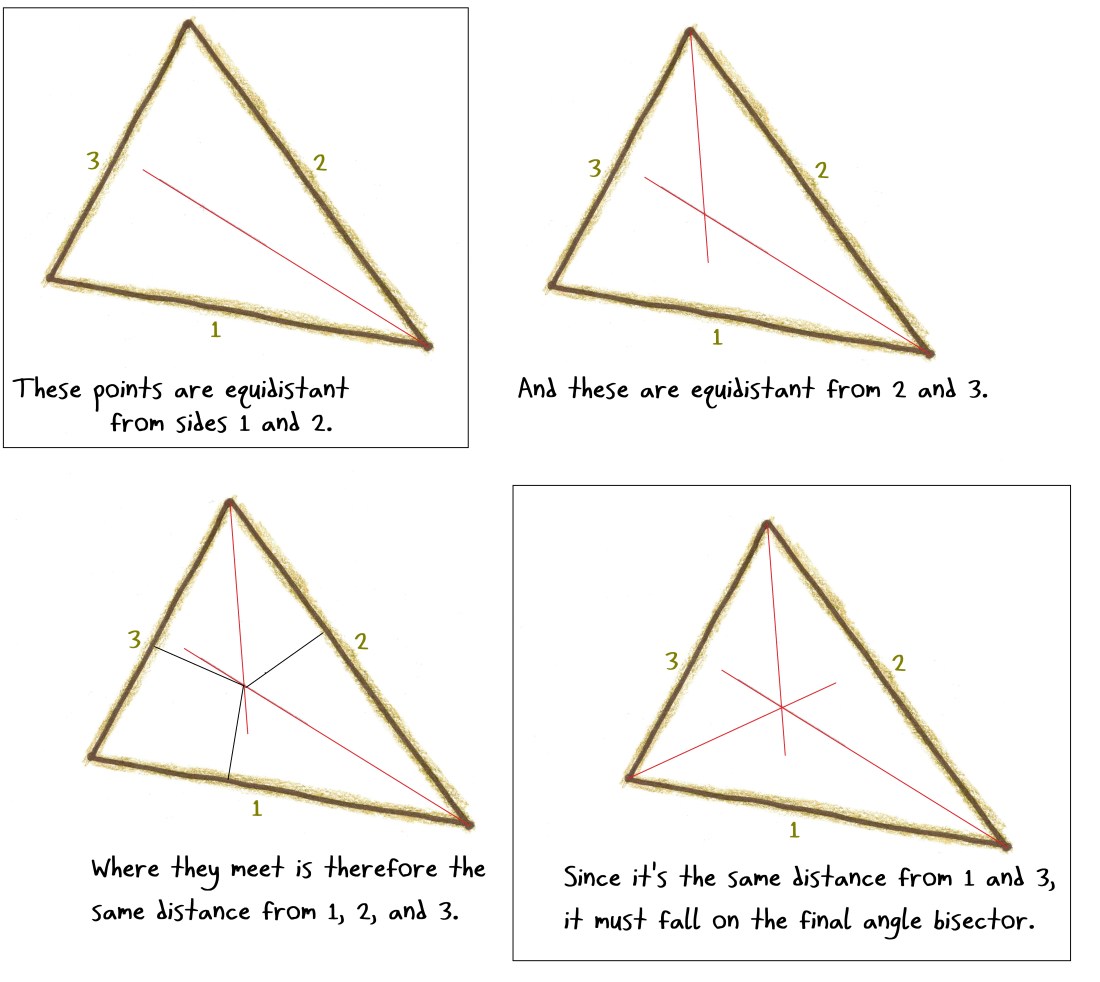
Both definitions work. It’s a question of where you want to push your bubble.
This goes way beyond triangles. Take the calculus of exponentials and logarithms. One approach to the logical development of these ideas, roughly mirroring the curricular sequence, would be this:

But a different axiomatic development works like this:
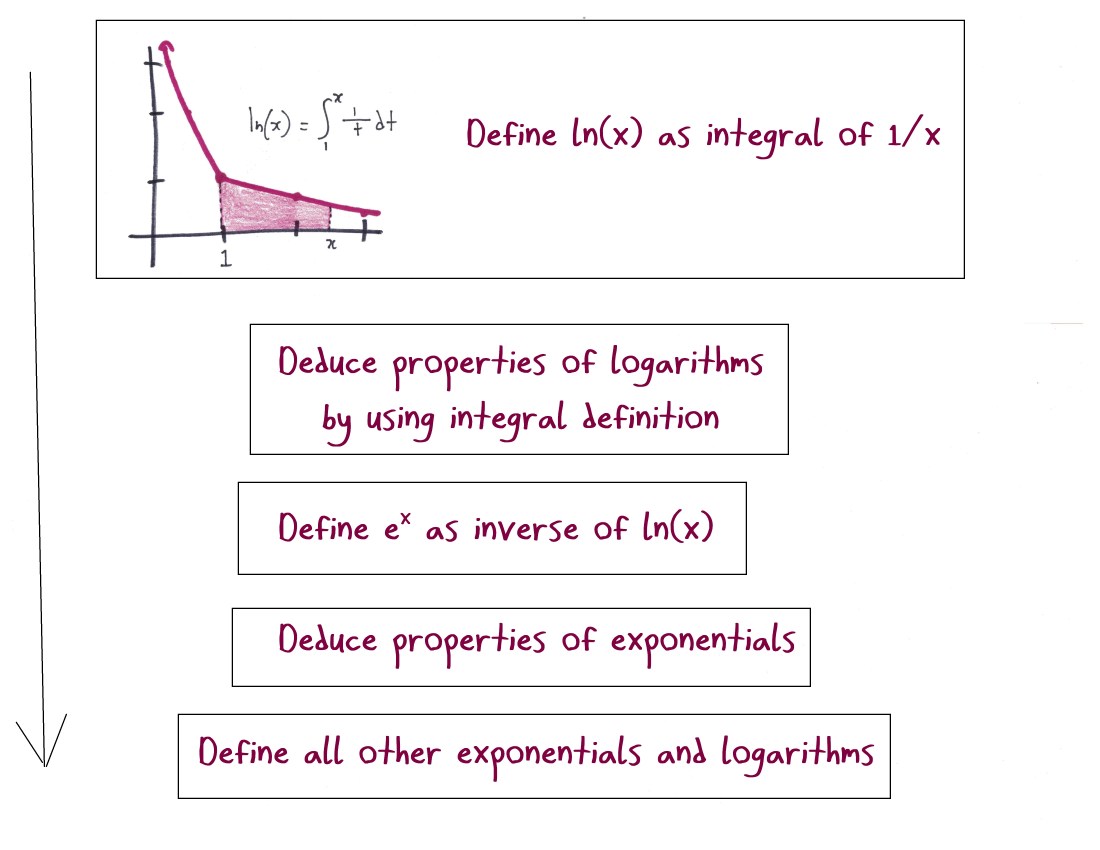
These two approaches arrive at the same mountaintop, but offer very different journeys. The first path starts flat and easy, but has a daunting elevation gain in the middle. The second path involves some tricky, technical climbing—but maintains a steadier level of difficulty.
What makes mathematics so cool—well, thing #467, anyway—is the perpetual process of bubble-smoothing. Some bubbles, with cleverness, can be smoothed away entirely. Others cannot; they are inescapable features of reality, permanent wrinkles in the rug of reason.
Who can help but love finding a knot in the fabric of logic?


I hate the normal distribution.
They say that “everything” is normally distributed… but it is not.
If heights of school children were truly normally distributed random variables, then there would be some possibility of a child of negative height. Which there aren’t.
Most data is not even close to normally distributed.
Consider the distribution of street addressees. There are lots of 2 and 3 digit street numbers, but 6 digit street numbers are not unheard of. It is a long, one-tailed distribution. And most of the stats I deal with fit this pattern. The, the distributions of wealth in an economy, the distribution of energy in earthquakes, the brightness of stars, they are long tailed, highly skewed distributions.
When is “everything normal?”
The central limit theorem says that if you average (or add) enough random variables together, the average will approximate a normal distribution….unless your variables are Cauchy.
Do you know what is normally distributed? errors. The normal distribution is the error function.
https://en.wikipedia.org/wiki/Error_function
Why don’t the exponential and the Pareto distribution get the kind of love they deserve.
Other odds and ends.
As a student, I was not at all comfortable that we could measure the area under a hyperbola and call it the very same thing as a completely different function we discussed in pre-calc the year earlier. Sure it has all the properties of a logarithm, but is it really the same thing? It was just a bit too hand-wavy, with not enough justification that we weren’t just cheating.
If logic is tied in a knot, are you capable of perceiving the knot if you are within that logical system. Or, do you need to be able to step outside the system to see the knot. Is the knot an intrinsic property or an extrinsic property?
Errors normal distributed? Please…
Another mathematical bubble to consider: should we be using tau (2 pi) as the fundamental circle constant, instead of pi? I vote in favor of tau. And with tau in place, it becomes debatable as to whether the standard normal or Gauss’s normal yields the simpler function. (I personally think it’s the standard normal.)
RE: “I like it up here! Shall we build a tower to reach?”
This is an adorable cartoon and very good and true. It also brings up an interesting question in philosophy of math. Of course, in logic/set theory, “fundamental” is reasonably well-defined. But using an ordinary human definition of “fundamental,” it’s fun to ask what the most fundamental mathematics is – as in, what math concepts do our brains grasp first in order to infer, construct, and apprehend the others. Symmetry is fundamental to group theory in this way. Numbers, especially natural numbers, are similarly fundamental. Euclidean distance is fundamental. How do we think of the other concepts in relation to these? Is a cyclic group just a weird kind of integer, or something to do with circles? Which meaning is the real one? This post is correct that, metaphysically, cold hard beautiful Truth-fully speaking, there is no *real* one. But don’t some of them *feel* a little more real? Which ones?
Reblogged this on softwaremechanic.
I was very pleased to discover I could actually understand everything here (at least until you got to deducing the properties of logarithms, but I get the idea).
I finally gave up on that Stats110 mooc. I need a far more hand-holdy approach, something between the first “Fat Chance” mooc and the “here’s a theorem and a proof, now go solve all these problems” thing. Or, just like with Calculus, I can only get so far, and no farther. 😦
Interesting interpretations
I got nerd snipped so hard that I spent a significant part of yesterday’s afternoon proving to myself the equality of both definitions of logarithm.
As Doug M mentions,
>As a student, I was not at all comfortable that we could measure the area under a hyperbola and call it the very same thing as a completely different function we discussed in pre-calc the year earlier. Sure it has all the properties of a logarithm, but is it really the same thing? It was just a bit too hand-wavy, with not enough justification that we weren’t just cheating.
I’ve had the same feeling recently. At any point, here is the result: https://github.com/NunoSempere/nunosempere.github.io/blob/master/maths-prog/logarithms.pdf
Thank you sir, your all post is very helpfull.
I solved my many problem by your advice.
I tooled my friend to flow you.