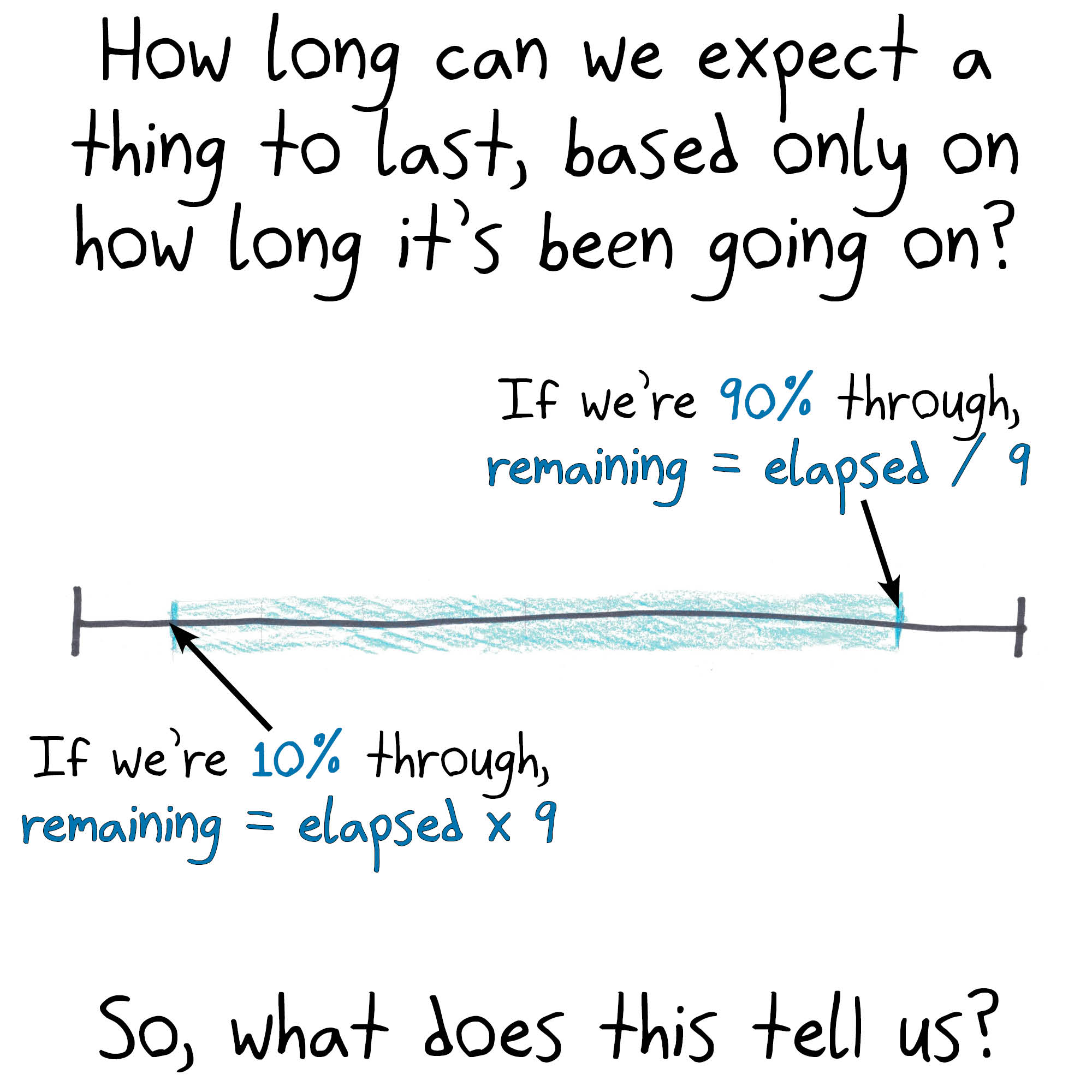
Relates to another problem I like: given k such serial numbers sampled uniformly from 1 through N, what is the most efficient way to estimate N?
(Tempting answer: “double the average of your data.” This is an unbiased estimator, but a fairly high-variance once; you can do better by just taking the largest number you’ve seen so far, and multiplying by (k+1)/k.)
Well, these are all very bad estimates in the sense that they take no information about the phenomenon itself into account… but if you have no such information, these are perfectly good estimates!
Here’s one that is somewhat relevant at the moment: When will the USA collapse? (Currently existing since 1776) The 80% Answer: Between 2053 and 4266. We have some time.








A closely related problem is: given the serial numbers of several captured tanks, how many tanks might the enemy have?
https://en.wikipedia.org/wiki/German_tank_problem
(This is why serial numbers, especially those of military equipment, usually aren’t really serial anymore.)
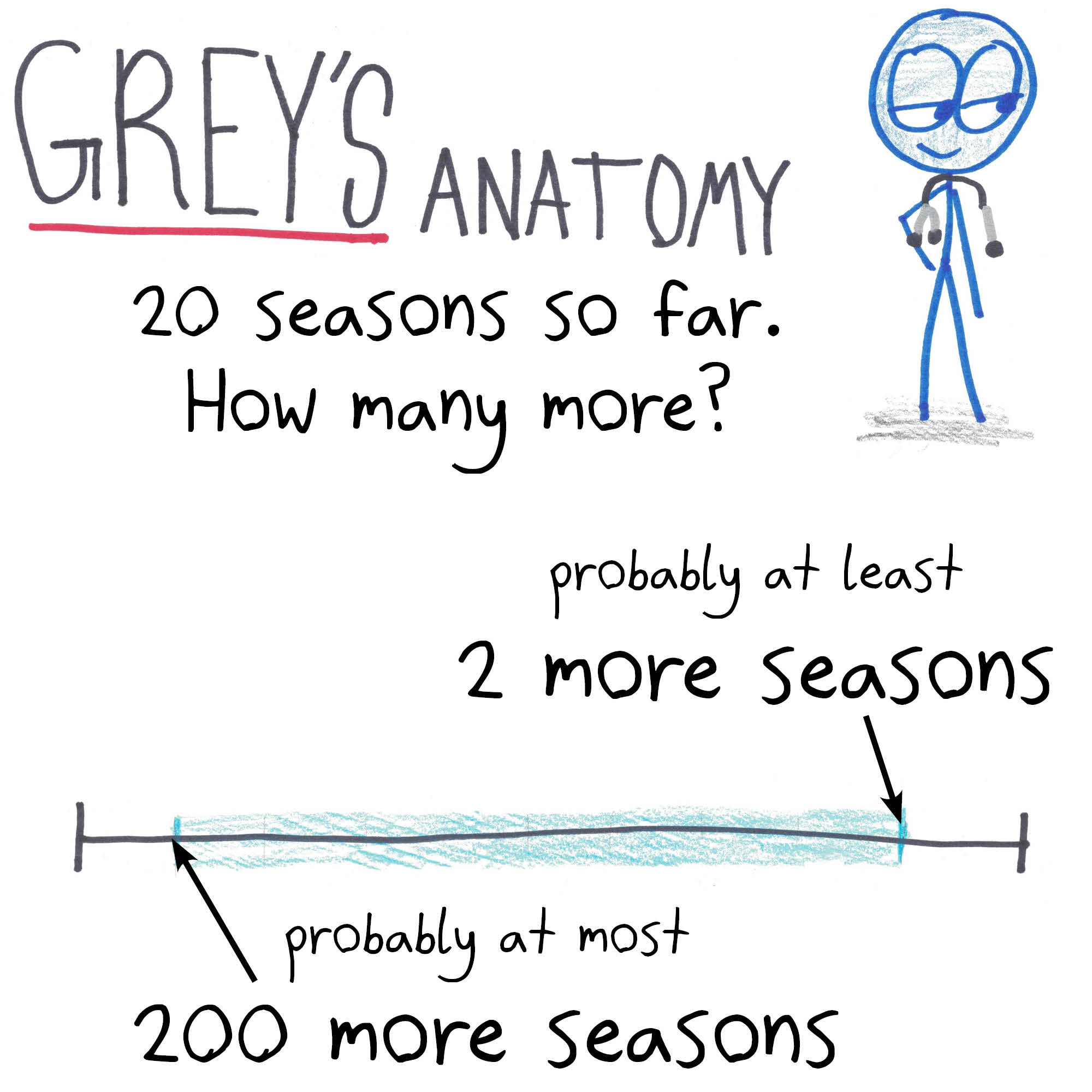
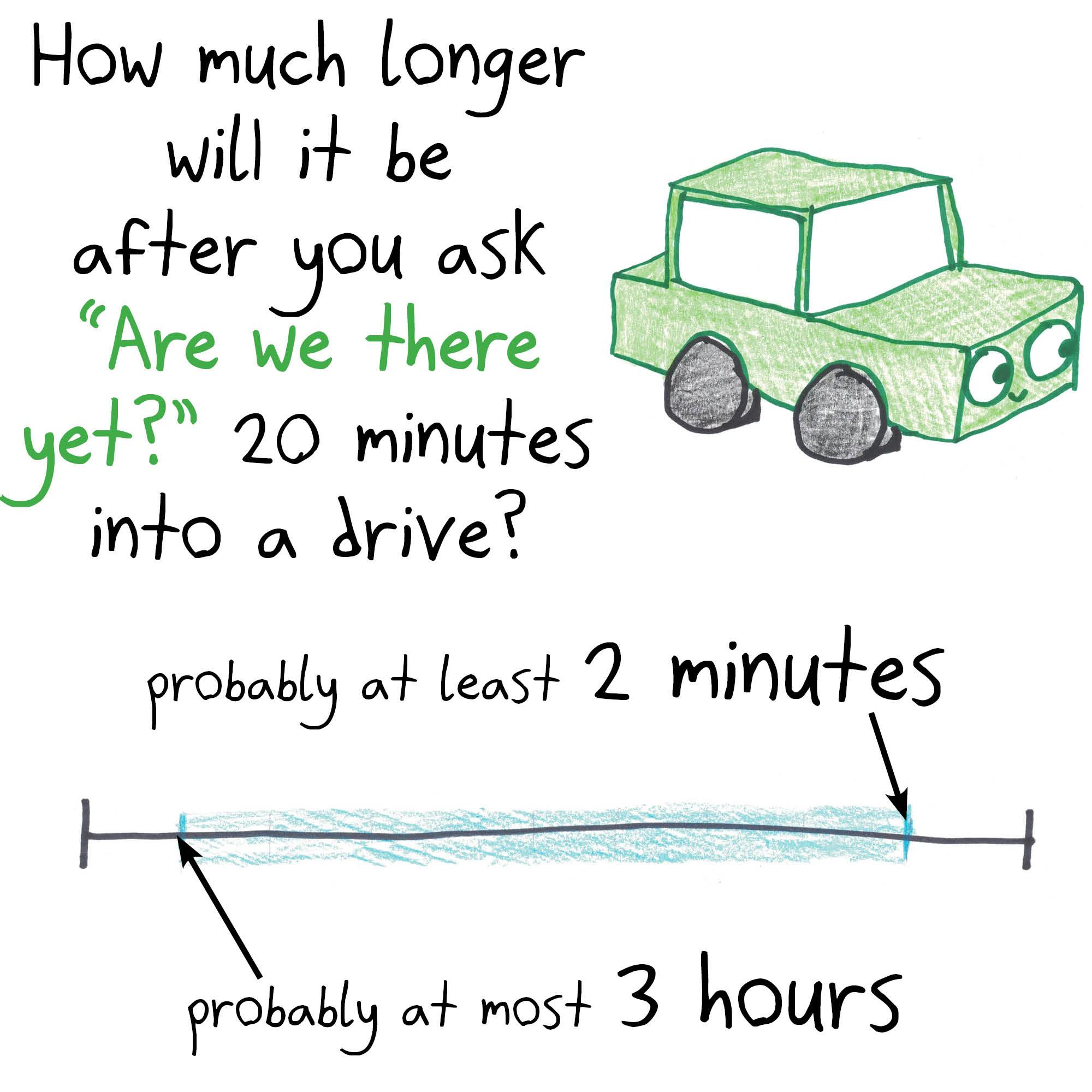
Oh yes, I love this one!
Relates to another problem I like: given k such serial numbers sampled uniformly from 1 through N, what is the most efficient way to estimate N?
(Tempting answer: “double the average of your data.” This is an unbiased estimator, but a fairly high-variance once; you can do better by just taking the largest number you’ve seen so far, and multiplying by (k+1)/k.)
😂😂
I was thinking that these are true … except if the process has an exponential lifetime. Right?
Well, these are all very bad estimates in the sense that they take no information about the phenomenon itself into account… but if you have no such information, these are perfectly good estimates!
Here’s one that is somewhat relevant at the moment: When will the USA collapse? (Currently existing since 1776) The 80% Answer: Between 2053 and 4266. We have some time.